
The classic Rubik’s Cube has 43,252,003,274,489,856,000 different states. You might well wonder how people are able to take a scrambled cube and bring it back to its original configuration, with just one color showing on each side. Some people are even able to do this blindfolded after viewing the scrambled cube once. Such feats are possible because there’s a basic set of rules that always allow someone to restore the cube to its original state in 20 moves or less.
Controlling a quantum computer is a lot like solving a Rubik’s Cube blindfolded: The initial state is well known, and there is a limited set of basic elements (qubits) that can be manipulated by a simple set of rules—rotations of the vector that represents the quantum state. But observing the system during those manipulations comes with a severe penalty: If you take a look too soon, the computation will fail. That’s because you are allowed to view only the machine’s final state.
The power of a quantum computer lies in the fact that the system can be put in a combination of a very large number of states. Sometimes this fact is used to argue that it will be impossible to build or control a quantum computer: The gist of the argument is that the number of parameters needed to describe its state would simply be too high. Yes, it will be quite an engineering challenge to control a quantum computer and to make sure that its state will not be affected by various sources of error. However, the difficulty does not lie in its complex quantum state but in making sure that the basic set of control signals do what they should do and that the qubits behave as you expect them to.
If engineers can figure out how to do that, quantum computers could one day solve problems that are beyond the reach of classical computers. Quantum computers might be able to break codes that were thought to be unbreakable. And they could contribute to the discovery of new drugs, improve machine-learning systems, solve fiendishly complex logistics problems, and so on.
The expectations are indeed high, and tech companies and governments alike are betting on quantum computers to the tune of billions of dollars. But it’s still a gamble, because the same quantum-mechanical effects that promise so much power also cause these machines to be very sensitive and difficult to control.
The main difference between a classical supercomputer and a quantum computer is that the latter makes use of certain quantum mechanical effects to manipulate data in a way that defies intuition.
Must it always be so? The main difference between a classical supercomputer and a quantum computer is that the latter makes use of certain quantum mechanical effects to manipulate data in a way that defies intuition. Here I will briefly touch on just some of these effects. But that description should be enough to help you understand the engineering hurdles—and some possible strategies for overcoming them.
Whereas ordinary classical computers manipulate bits (binary digits), each of which must be either 0 or 1, quantum computers operate on quantum bits, or qubits. Unlike classical bits, qubits can take advantage of a quantum mechanical effect called superposition, allowing a qubit to be in a state where it has a certain amount of zero-ness to it and a certain amount of one-ness to it. The coefficients that describe how much one-ness and how much zero-ness a qubit has are complex numbers, meaning that they have both real and imaginary parts.
In a machine with multiple qubits, you can create those qubits in a very special way, such that the state of one qubit cannot be described independently of the state of the others. This phenomenon is called entanglement. The states that are possible for multiple entangled qubits are more complicated than those for a single qubit.
While two classical bits can be set only to 00, 01, 10, or 11, two entangled qubits can be put into a superposition of these four fundamental states. That is, the entangled pair of qubits can have a certain amount of 00-ness, a certain amount of 01-ness, a certain amount of 10-ness, and a certain amount of 11-ness. Three entangled qubits can be in a superposition of eight fundamental states. And n qubits can be in a superposition of 2n states. When you perform operations on these n entangled qubits, it’s as though you were operating on 2n bits of information at the same time.
The operations you do on a qubit are akin to the rotations done to a Rubik’s Cube. A big difference is that the quantum rotations are never perfect. Because of certain limitations in the quality of the control signals and the sensitivity of the qubits, an operation intended to rotate a qubit by 90 degrees may end up rotating it by 90.1 degrees or by 89.9 degrees, say. Such errors might seem small but they quickly add up, resulting in an output that is completely incorrect.
Another source of error is decoherence: Left by themselves, the qubits will gradually lose the information they contain and also lose their entanglement. This happens because the qubits interact with their environment to some degree, even though the physical substrate used to store them has been engineered to keep them isolated. You can compensate for the effects of control inaccuracy and decoherence using what’s known as quantum error correction, but doing so comes at great cost in terms of the number of physical qubits required and the amount of processing that needs to be done with them.
Once these technical challenges are overcome, quantum computers will be valuable for certain special kinds of calculations. After executing a quantum algorithm, the machine will measure its final state. This measurement, in theory, will yield with high probability the solution to a mathematical problem that a classical computer could not solve in a reasonable period of time.
So how do you begin designing a quantum computer? In engineering, it’s good practice to break down the main function of a machine into groups containing subfunctions that are similar in nature or required performance. These functional groups then can be more easily mapped onto hardware. My colleagues and I at QuTech in the Netherlands have found that the functions needed for a quantum computer can naturally be divided into five such groups, conceptually represented by five layers of control. Researchers at IBM, Google, Intel, and elsewhere are following a similar strategy, although other approaches to building a quantum computer are also possible.
Let me describe that five-layer cake, starting at the top, the highest level of abstraction from the nitty-gritty details of what’s going on deep inside the hardware.
At the top of the pile is the application layer, which is not part of the quantum computer itself but is nevertheless a key part of the overall system. It represents all that’s needed to compose the relevant algorithms: a programming environment, an operating system for the quantum computer, a user interface, and so forth. The algorithms composed using this layer can be fully quantum, but they may also involve a combination of classical and quantum parts. The application layer should not depend on the type of hardware used in the layers under it.
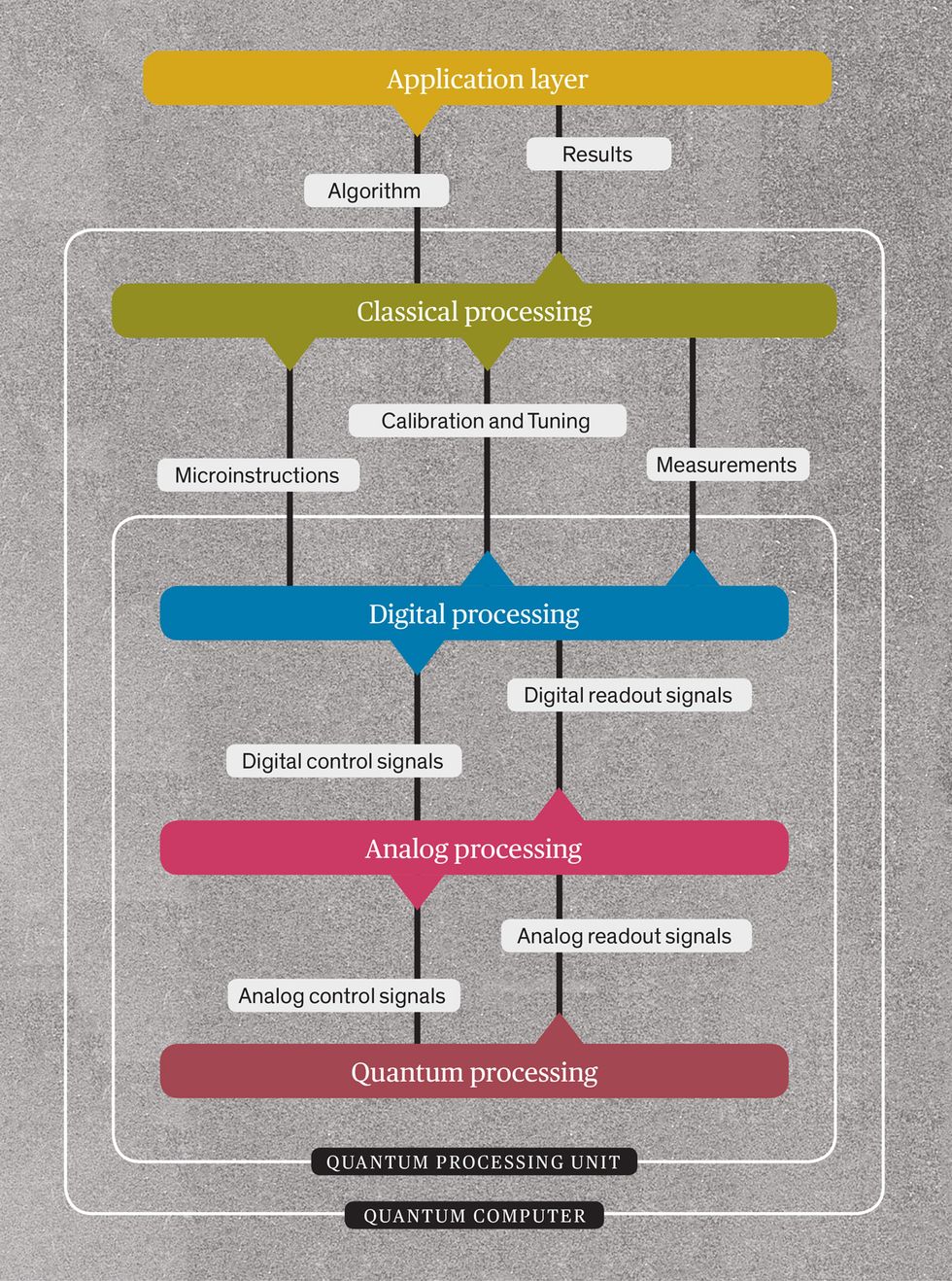
Layer Cake: The components of a practical quantum computer can be divided into five sections, each carrying out different kinds of processing.
Illustration: Chad Hagen
Directly below the application layer is the classical-processing layer, which has three basic functions. First, it optimizes the quantum algorithm being run and compiles it into microinstructions. That’s analogous to what goes on in a classical computer’s CPU, which processes many microinstructions for each machine-code instruction it must carry out. This layer also processes the quantum-state measurements returned by the hardware in the layers below, which may be fed back into a classical algorithm to produce final results. The classical-processing layer will also take care of the calibration and tuning needed for the layers below.
Underneath the classical layer are the digital-, analog-, and quantum-processing layers, which together make up a quantum processing unit (QPU). There is a tight connection between the three layers of the QPU, and the design of one will depend strongly on that of the other two. Let me describe more fully now the three layers that make up the QPU, moving from the top downward.
The digital-processing layer translates microinstructions into pulses, the kinds of signals needed to manipulate qubits, allowing them to act as quantum logic gates. More precisely, this layer provides digital definitions of what those analog pulses should be. The analog pulses themselves are generated in the QPU’s analog-processing layer. The digital layer also feeds back the measurement results of the quantum calculation to the classical-processing layer above it, so that the quantum solution can be combined with results computed classically.
Right now, personal computers or field-programmable gate arrays can handle these tasks. But when error correction is added to quantum computers, the digital-processing layer will have to become much more complicated.
The analog-processing layer creates the various kinds of signals sent to the qubits, one layer below. These are mainly voltage steps and sweeps and bursts of microwave pulses, which are phase and amplitude modulated so as to execute the required qubit operations. Those operations involve qubits connected together to form quantum logic gates, which are used in concert to carry out the overall computation according to the particular quantum algorithm that is being run.
Although it’s not technically difficult to generate such a signal, there are significant hurdles here when it comes to managing the many signals that would be needed for a practical quantum computer. For one, the signals sent to the different qubits would need to be synchronized at picosecond timescales. And you need some way to convey these different signals to the different qubits so as to be able to make them do different things. That’s a big stumbling block.
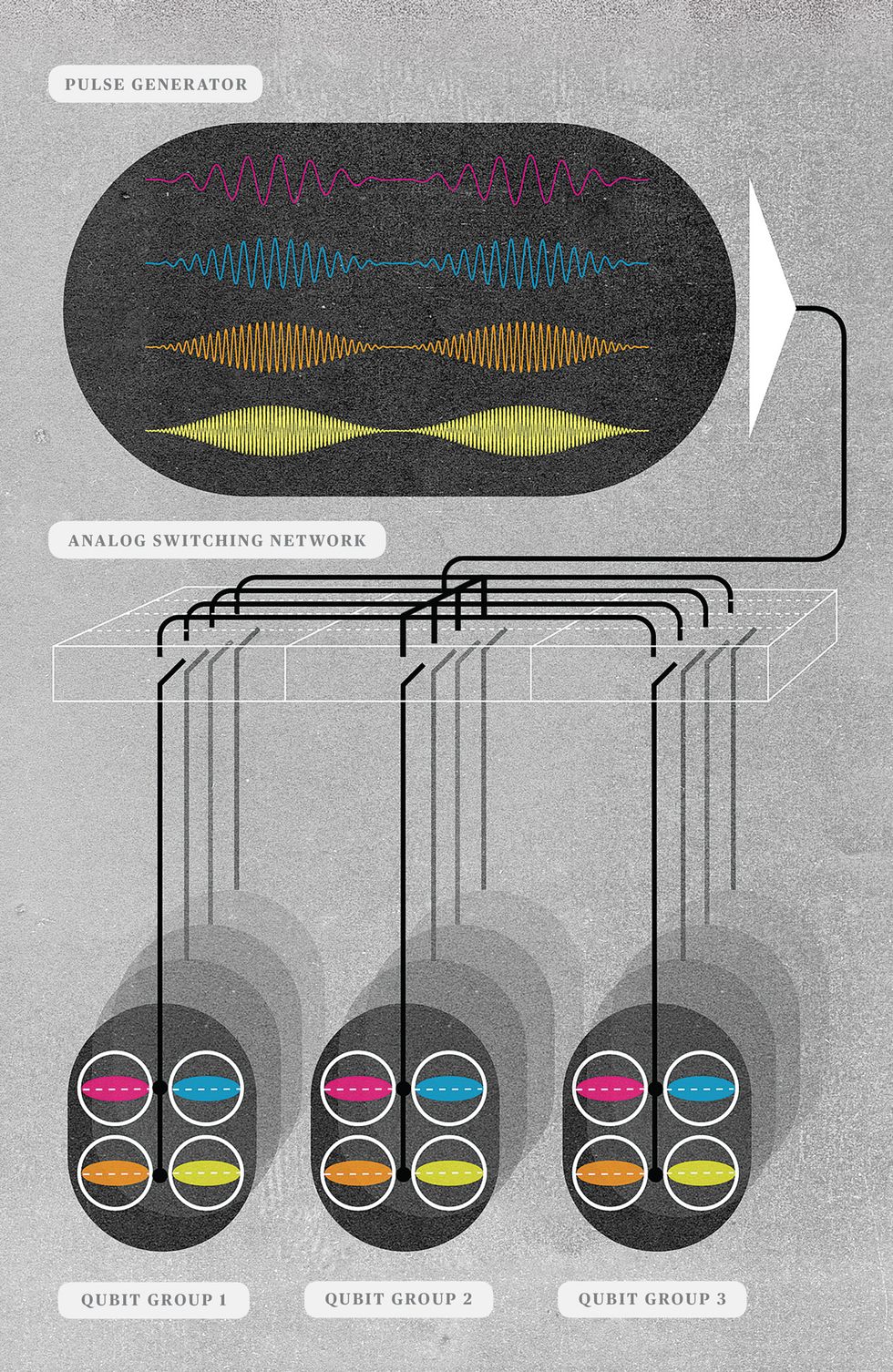
Divide and Conquer: In a practical quantum computer, there will be too many qubits to attach separate signal lines to each of them. Instead, a combination of spatial and frequency multiplexing will be used. Qubits will be fabricated in groups attached to a common signal line, with each qubit in a group tuned to respond to signals of just one frequency (shown here as one color). The computer can then manipulate a subset of its qubits by generating pulses of one particular frequency and using an analog switching network to send these pulses only to certain qubit groups.
Illustration: Chad Hagen
In today’s small-scale systems, with just a few dozen qubits, each qubit is tuned to a different frequency—think of it as a radio receiver locked to one channel. You can select which qubit to address on a shared signal line by transmitting at its special frequency. That works, but this strategy doesn’t scale. You see, the signals sent to a qubit must have a reasonable bandwidth, say, 10 megahertz. And if the computer contains a million qubits, such a signaling system would need a bandwidth of 10 terahertz, which of course isn’t feasible. Nor would it be possible to build in a million separate signal lines so that you could attach one to each qubit directly.
The solution will probably involve a combination of frequency and spatial multiplexing. Qubits would be fabricated in groups, with each qubit in the group being tuned to a different frequency. The computer would contain many such groups, all attached to an analog communications network that allows the signal generated in the analog layer to be connected only to a selected subset of groups. By arranging the frequency of the signal and the network connections correctly, you can then manipulate the targeted qubit or set of qubits without affecting the others.
That approach should do the job, but such multiplexing comes with a cost: inaccuracies in control. It remains to be determined how such inaccuracies can be overcome.
In current systems, the digital- and analog-processing layers operate mainly at room temperature. Only the quantum-processing layer beneath them, the layer holding the qubits, is kept near absolute zero temperature. But as the number of qubits increases in future systems, the electronics making up all three of these layers will no doubt have to be integrated into one packaged cryogenic chip.
Some companies are currently building what you might call pre-prototype systems, based mainly on superconducting qubits. These machines contain a maximum of a few dozen qubits and are capable of executing tens to hundreds of coherent quantum operations. The companies pursuing this approach include tech giants Google, IBM, and Intel.
By extending the number of control lines, engineers could expand current architectures to a few hundred qubits, but that’s the very most. And the short time that these qubits remain coherent—today, roughly 50 microseconds—will limit the number of quantum instructions that can be executed before the calculation is consumed by errors.
Given these limitations, the main application I anticipate for systems with a few hundred qubits will be as an accelerator for conventional supercomputers. Specific tasks for which the quantum computer runs faster will be sent from a supercomputer to the quantum computer, with the results then returned to the supercomputer for further processing. The quantum computer will in a sense act like the GPU in your laptop, doing certain specific tasks, like matrix inversion or optimization of initial conditions, a lot faster than the CPU alone ever could.
During this next phase in the development of quantum computers, the application layer will be fairly straightforward to build. The digital-processing layer will also be relatively simple. But building the three layers that make up the QPU will be tricky.
Current fabrication techniques cannot produce completely uniform qubits. So different qubits have slightly different properties. That heterogeneity in turn requires the analog layer of the QPU to be tailored to the specific qubits it controls. The need for customization makes the process of building a QPU difficult to scale. Much greater uniformity in the fabrication of qubits would remove the need to customize what goes on in the analog layer and would allow for the multiplexing of control and measurement signals.
Multiplexing will be required for the large numbers of qubits that researchers will probably start introducing in 5 to 10 years so that they can add error correction to their machines. The basic idea behind such error correction is simple enough: Instead of storing the data in one physical qubit, multiple physical qubits are combined into one error-corrected, logical qubit.
Quantum error correction could solve the fundamental problem of decoherence, but it would require anywhere from 100 to 10,000 physical qubits per logical qubit. And that’s not the only hurdle. Implementing error correction will require a low-latency, high-throughput feedback loop that spans all three layers of the QPU.
It remains to be seen which of the many types of qubits being experimented with now—superconducting circuits, spin qubits, photonic systems, ion traps, nitrogen-vacancy centers, and so forth—will prove to be the most suitable for creating the large numbers of qubits needed for error correction. Regardless of which one proves best, it’s clear that success will require packaging and controlling millions of qubits if not more.
Which brings us to the big question: Can that really be done? The millions of qubits would have to be controlled by continuous analog signals. That’s hard but by no means impossible. I and other researchers have calculated that if device quality could be improved by a few orders of magnitude, the control signals used to perform error correction could be multiplexed and the design of the analog layer would become straightforward, with the digital layer managing the multiplexing scheme. These future QPUs would not require millions of digital connections, just some hundreds or thousands, which could be built using current techniques for IC design and fabrication.
The bigger challenge could well prove to be the measurement side of things: Many thousands of measurements per second would need to be performed on the chip. These measurements would be designed so that they do not disturb the quantum information (which remains unknown until the end of the calculation) while at the same time revealing and correcting any errors that arise along the way. Measuring millions of qubits at this frequency will require a drastic change in measurement philosophy.
The current way of measuring qubits requires the demodulation and digitization of an analog signal. At the measurement rate of many kilohertz, and with millions of qubits in a machine, the total digital throughput would be petabytes per second. That’s far too much data to handle using today’s techniques, which involve room-temperature electronics connected to the chip holding the qubits at temperatures near absolute zero.
Clearly, the analog and digital layers of the QPU will have to be integrated with the quantum-processing layer on the same chip, with some clever schemes implemented there for preprocessing and multiplexing the measurements. Fortunately, for the processing that is done to correct errors, not all qubit measurements would have to be passed up to the digital layer. That only needs to be done when local circuity detects an error, which drastically reduces the required digital bandwidth.
What goes on in the quantum layer will fundamentally determine how well the computer will operate. Imperfections in the qubits mean that you’ll need more of them for error correction, and as those imperfections get worse, the requirements for your quantum computer explode beyond what is feasible. But the converse is also true: Improvements in the quality of the qubits might be costly to engineer, but they would very quickly pay for themselves.
In the current pre-prototyping phase of quantum computing, individual qubit control is still unavoidable: It’s required to get the most out of the few qubits that we now have. Soon, though, as the number of qubits available increases, researchers will have to work out systems for multiplexing control signals and the measurements of the qubits.
The next significant step will be the introduction of rudimentary forms of error correction. Initially, there will be two parallel development paths, one with error correction and the other without, but error-corrected quantum computers will ultimately dominate. There’s simply no other route to a machine that can perform useful, real-world tasks.
To prepare for these developments, chip designers, chip-fabrication-process engineers, cryogenic-control specialists, experts in mass data handling, quantum-algorithm developers, and others will need to work together closely.
Such a complex collaboration would benefit from an international quantum-engineering road map. The various tasks required could then be assigned to the different sets of specialists involved, with the publishers of the road map managing communication between groups. By combining the efforts of academic institutions, research institutes, and commercial companies, we can and will succeed in building practical quantum computers, unleashing immense computing power for the future.
This article appears in the April 2020 print issue as “Quantum Computers Scale Up.”
